
Your AI content engine is only as good as its context
Building a context layer

Hello all 👋
I did a session with the ColdIQ team recently on how I am using Hermes inside Trigify.
The headline was content. The real topic was context.
People are still treating AI content like a better writing assistant. They open Claude, paste in a prompt, maybe add a few examples, then wonder why everything still sounds generic.
That is backwards.
The writing is the last mile. The thing that decides whether the output is useful is everything that happened before the prompt.
For me, the system now looks like this:
Context layer
Brain system
Skill library
Suggestions
Cross channel activation
Performance feedback back into the system
The Content OS is what people see.
The Context Engine is why it works.

The mistake most teams make with AI content
Most AI content systems start with a workflow.
A prompt for LinkedIn.
A prompt for blog posts.
A prompt for newsletters.
A prompt for repurposing webinars.
That works for about a week.
Then the same problem appears again. The model can write, but it does not know what matters. It does not know what your market is talking about this week. It does not know what customers asked on calls. It does not know which posts drove signups, which ones pulled comments from the wrong audience, or which topics are getting tired.
So the system slowly becomes a content treadmill.
More drafts.
More variations.
More fake productivity.
The problem is not the model. Most of the good models are already smart enough for the work. The problem is the harness around the model.
If the harness has no live context, no memory, no feedback loop, and no way to improve its own process, then you are still starting from zero every time.
That is the part I wanted to fix.
Layer 1: The context engine
The first layer is raw context.
This is the part I care about most because it is where the useful signal comes from.
I split it into two buckets:
internal context
external context
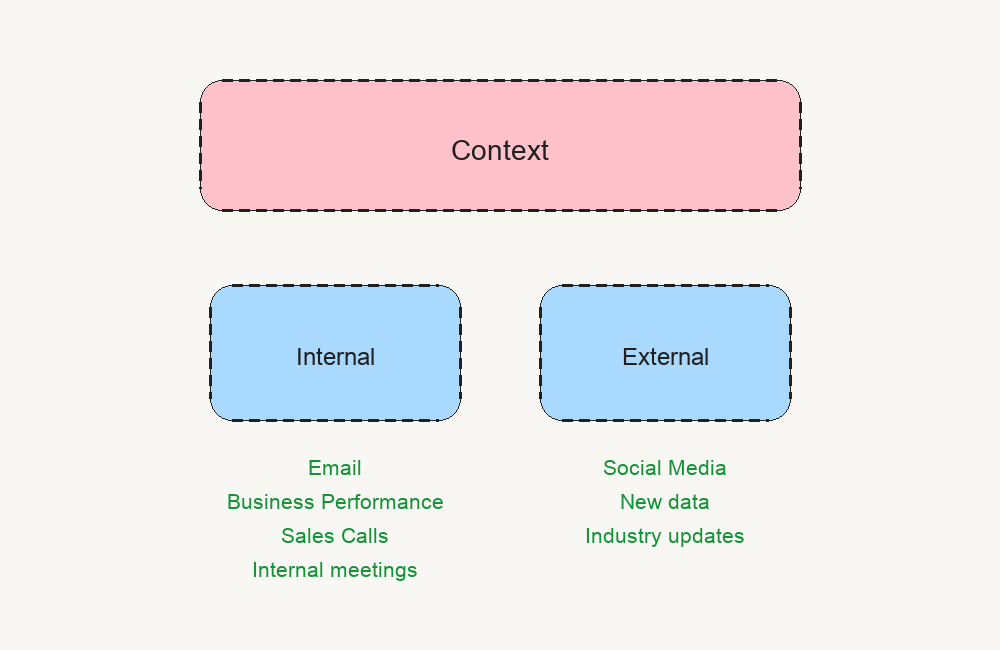
Internal context is everything that already exists inside the business.
For us that means:
Fireflies call transcripts
customer and partner conversations
email and Slack context
Featurebase and product feedback
support friction
product releases
post performance
pipeline and signup data
External context is everything happening outside the business.
For us that means:
LinkedIn posts
X posts
YouTube videos
Substack posts
Reddit threads
competitor content
creator posts
industry news
market trends
The trick is not to dump all of that into a prompt.
That would be chaos.
The trick is to watch the right sources, store the raw evidence, and then let the system decide what deserves to become durable knowledge.
This is where Trigify is obviously useful for us. We can monitor people, profiles, keywords, competitors, customer conversations, and social engagement. Fast moving social data tells us what is gaining steam. Longer form content tells us why it matters.
Fast social gives you the topic.
Long form gives you the understanding.
That distinction matters.
A LinkedIn post might show that everyone is suddenly talking about Claude Code for AEO. Useful signal. But it will not usually explain the full workflow. For that, I want the YouTube video, the Substack article, the Reddit thread, or the podcast where someone actually walks through what they built.
So the context engine is constantly asking:
what is gaining momentum?
who is saying it?
is this relevant to our ICP?
does this connect to something we already know?
should this become memory, an idea, a workflow, or a sales trigger?
Without that layer, AI content is basically autocomplete with confidence.
Layer 2: The brain system
The second layer is the brain.
This is the part that stops the system from drowning in its own inputs.
I use an Obsidian and markdown style knowledge base for this. The exact tool matters less than the structure.
The structure matters a lot.
Raw evidence stays raw.
Transcripts, exports, source dumps, social posts, search results, call notes, product feedback. Those do not automatically become memory. They sit as source material.
Then the system periodically runs a brain sweep.
It reads the new raw inputs and asks:
is this new?
does it support an existing belief?
does it contradict something we thought was true?
is it useful for future content, product, sales, or positioning?
should it update a wiki page?
should it stay as raw evidence only?
Durable patterns become wiki pages.
Temporary noise stays raw.
That is the bloat control.
Without it, your memory system becomes a junk drawer. Everything is technically stored, but nothing is easy to trust.
The brain has a few simple jobs:
keep a canonical log of what happened
turn raw evidence into sourced knowledge
connect related concepts together
give agents something to read before they act
prune or downgrade things that stop mattering
This is the difference between giving an agent a pile of documents and giving it a company brain.
A pile of documents is retrieval.
A brain is judgement with provenance.
That is why I do not want agents pulling random context from random folders every time they work. I want them to read the right pages, understand the current beliefs, check the source material when needed, and then act.
Layer 3: The skill library
Skills are useful.
They are just not the whole thing.
This is where a lot of the current AI content is getting a bit silly. Everyone is talking about skills like they are the operating system. They are not. A skill is a playbook.
It tells the agent how to do something.
That could be:
how to write in my style
how to create a LinkedIn post
how to research a competitor
how to QA a blog draft
how to use the Trigify CLI
how to update the brain
how to turn a webinar transcript into a Substack draft
Useful. Very useful.
But a skill without context is still weak.
If I give an agent the perfect LinkedIn writing skill, but it has no idea what is happening in the market, what our customers care about, what performed last week, or what I actually believe, the output will still be average.
The skill tells it how to work.
The brain tells it what we know.
The context engine tells it what changed.
That combination is where the quality jump happens.
The other important part is that skills should not be static.
If the agent misses something, the skill should get patched.
If a format underperforms for three weeks, the skill should change.
If a new workflow works better, the skill should absorb it.
This is the loop I care about:
run the workflow
inspect the output
compare against results
identify the miss
update the playbook
use the better version next time
No task should start from zero twice.
Layer 4: suggestions
Once the context, brain, and skills are in place, the obvious output is content suggestions.
But I do not want generic ideas.
I want ideas with a reason behind them.
A useful suggestion should tell me:
what to create
why now
where the signal came from
which audience it is for
what proof we have
what hook angle to use
what CTA makes sense
which channel it belongs on
whether it should trigger any GTM follow up
That last point matters.
Content should not live in a marketing silo.
If someone comments on a post, if a target account engages, if a competitor narrative starts moving, if a customer pain keeps appearing in calls, that can be a content idea and a sales signal.
The same context should be useful across:
LinkedIn posts
X posts
Substack essays
YouTube topics
webinar angles
sales follow up
CRM routing
internal Slack alerts
product feedback
That is why I do not think about this as a content calendar.
A calendar is a schedule.
This is an operating system.
Layer 5: cross channel activation
Once the system knows what matters, it can decide where that context should go.
The same underlying insight might become:
a founder POV on LinkedIn
a sharper take on X
a deeper Substack post
a YouTube explainer
a webinar narrative
a sales enablement note
a CRM trigger
a follow up message
a product feedback summary
Different channels need different packaging.
LinkedIn wants a founder POV, a proof point, and a reason to care quickly.
X wants a sharper take and less explanation.
Substack can carry the full system.
YouTube needs search intent and a clear promise.
Sales needs the trigger, the account context, and the next action.
The system should not paste the same content everywhere. It should route the same context into different outputs.
That is the part most repurposing workflows miss.
Repurposing is usually format conversion.
This is context routing.
Why Hermes sits at the centre of it
I moved the team onto Hermes because I wanted a general agent harness, not another coding assistant.
Claude Code and Codex are useful. I still use them. But I mostly treat them as specialist workers.
Hermes is the orchestrator.
The big reasons:
it is always on
it can run crons
it can talk through Discord and Slack
it can use different models for different jobs
it can call tools and APIs
it can manage subagents
it can read and update skills
it can sit on a dedicated Mac Mini with its own permissions
it can keep improving the operating system around the work
The model switching point is underrated.
I do not want tribalism around models. OpenAI, Anthropic, Chinese open source models, smaller cheap models, they all have different strengths.
Some are better at tool calling.
Some are better at writing.
Some are good enough for cheap classification.
Some are better for coding.
Hermes lets me route the work instead of pretending one model should do everything.
So the main agent can think and orchestrate. A writing subagent can draft in the style I prefer. A cheaper model can classify signals. Codex can handle a coding task. Another agent can QA the output.
That is closer to how a team works.
What this looks like in practice
Here is a simple content workflow.
1. Trigify monitors the market
It watches the people, topics, competitors, and social signals we care about.
A post starts moving. A creator says something useful. A competitor narrative appears. A customer problem shows up repeatedly.
2. Hermes stores the raw evidence
The raw item is saved. The transcript, post, source, URL, author, engagement, and context are kept as evidence.
3. The brain sweep decides what matters
The system asks whether this is a one off or a pattern.
If it is durable, it updates the wiki.
If it is temporary, it stays raw.
If it is immediately useful, it becomes an idea or task.
4. The skill library shapes the output
The content skill decides how to package it.
For me, that usually means proof first. Commercial tension early. Mechanism second.
Not “here is my AI stack”.
More like:
“A YouTube video did 26x its usual performance because the system knew what the market cared about before I recorded it.”
Then explain the system.
5. The suggestion lands in the right place
It might go to Notion as an idea.
It might become a LinkedIn draft.
It might become a Substack post.
It might become a Slack alert.
It might become a sales workflow.
6. Performance feeds back in
The system looks at what happened.
Did it get comments?
Did it get the right comments?
Did it drive signups?
Did it create pipeline?
Did the hook work?
Did the audience care about the topic or the proof point?
Then it updates memory and skills.
That is the loop.
The AI SDR version is the same pattern
This is not only for content.
The AI SDR version works the same way.
The inputs are different, but the architecture is the same:
public signal
company context
ICP judgement
message playbook
routed action
performance feedback
If someone raises funding, changes role, comments on a relevant post, hires for a GTM role, launches a new product, or starts talking about a problem we solve, that can be a useful signal.
But the signal alone is not enough.
Bad outbound happens when teams treat every public event as intent.
Good outbound needs judgement.
Who is the person?
What company are they at?
Do they fit the ICP?
What did they actually say?
Is there a real reason to reach out now?
What internal context do we have?
What should happen next?
That is why the same brain matters for sales.
If an AI SDR knows the product, the market, the ICP, the objections from sales calls, the current positioning, and the public signal, it can write and route a much better message.
If it only knows the trigger, it will spam people with fake relevance.
There is a huge difference.
The cost of doing this badly
The danger with AI agents is not that they cannot do work.
It is that they can do bad work at scale.
A weak content agent produces more generic posts.
A weak sales agent sends more irrelevant emails.
A weak research agent fills the brain with junk.
A weak memory system makes every future task worse because the agent starts trusting bad context.
That is why I care so much about the architecture.
The system needs permissions, source control, bloat control, human review, and feedback loops.
Especially if it is always on.
I run Hermes on a separate machine because I want the agent environment separated from my main computer. It has its own accounts, its own access, and its own constraints. Most sensitive tools are read first unless I explicitly decide otherwise.
If you give an always on agent access to everything on your main machine, do not be surprised when it eventually touches something you wish it had not touched.
Useful agents need context.
Safe agents need boundaries.
You need both.
The setup I would recommend
If I were starting again, I would not begin with 40 crons and a giant brain.
I would start smaller.
First, build the context map.
What should the agent know?
Split it into internal and external:
Internal:
customer calls
sales calls
product feedback
email and Slack themes
support issues
performance data
current positioning
ICP notes
External:
competitors
creators
keywords
customer communities
Reddit and Substack
LinkedIn and X
YouTube and podcasts
industry news
Second, create the brain structure.
Keep raw evidence separate from durable knowledge.
You need:
raw folder
wiki folder
log
index
source links
confidence labels
rules for when something becomes memory
Third, create only a few skills.
Start with the workflows you already repeat:
write a LinkedIn post
draft a newsletter
research a competitor
summarize customer calls
create content ideas
QA a draft before publishing
Fourth, add crons slowly.
Do not automate everything immediately.
Start with:
daily raw signal intake
daily or twice daily brain sweep
weekly content performance review
weekly skill improvement review
Fifth, keep a human in the loop for anything external.
Drafts are fine.
Suggestions are fine.
Internal summaries are fine.
Publishing, emailing, posting, and changing customer facing systems should require approval until the system has earned trust.
The actual point
The best AI content system is not the one with the best prompt.
It is the one with the best context loop.
That means:
it watches the market
it remembers what matters
it learns how you work
it turns signal into decisions
it routes context across channels
it measures outcomes
it updates itself when it is wrong
That is why I am using Hermes this way.
Not because I need another chatbot.
Because I want an agent that can operate with context, memory, skills, and feedback.
Writing is one output.
The bigger play is turning the company into a system that gets smarter every week.